Running a PET analysis using the python client
Last updated on 2024-07-09 | Edit this page
Overview
Questions
- How to check the status of a given collaboration within vantage6, programatically, using the Python client?
- How to request a task based on a given algorithm, programatically, through vantage6’s Python client?
Objectives
- Understand the programmatic approach for performing a data analysis through a given scenario.
Vantage6 Python client - basic concepts
The vantage6 Python client is a library designed to facilitate interaction with the vantage6 server, to perform various tasks such as creating computation tasks, managing organizations, collaborations, users, and collecting results. It is a versatile alternative to the web-based user interface which enable users and administrators to manage resources programatically, e.g., for automating actions or integrating them on other applications. It communicates with the server through its REST API, handling encryption and decryption of data for secure operations.
Creating an instance of the vantage6 Python client is relatively straightforward, requiring only (after installing the corresponding libraries) to define the server connection details: server URL, login credentials, and the organization’s private key (if encryption is being used). In case the server has the two-factor authentication (2FA) enabled you should also enter the corresponding time-based one-time password accordingly.
For simplicity, these settings can be defined on a separate Python module like the following:
PYTHON
# config.py
server_url = "https://<vantage6-server-address>"
server_port = 443
server_api = "/api"
username = "MY USERNAME"
password = "MY PASSWORD"
organization_key = "" # Path to the encryption key, if encryption is enabled.Once you have created the Python module with the configuration settings, you can create the client instance as follows:
PYTHON
from vantage6.client import UserClient as Client
# Note: we assume here the config.py you just created is in the current directory.
# If it is not, then you need to make sure it can be found on your PYTHONPATH
import config
# Initialize the client object, and run the authentication
client = Client(config.server_url, config.server_port, config.server_api,
log_level='debug')
client.authenticate(config.username, config.password)
# Setup the encryption, if you have an organization_key (e.g., use the one set on the config.py file). If not, use None.
# Note that this will be optional in future versions (no need to use setup_encription at all when no organization keys are used) when Change Request vantage6/vantage6#1302 is addressed.
#client.setup_encryption(config.organization_key)
client.setup_encryption(None)
Using the client
The client instance, once created, offers a set of attributes that correspond to the vantage6 core concepts (See Chapter #3’s concept map):
client.userclient.organizationclient.ruleclient.roleclient.collaborationclient.taskclient.resultclient.utilclient.node
Each of these attributes, in turn, provides an abstraction of the CRUD (Create, Read, Update, and Delete) operations that can be performed to its corresponding concept*:
PYTHON
# Get all the instances of the given '<resource>' in the server. For example, client.task.organization() returns all the organizations registered on the server.
client.<resource>.list()(*) Please note that some resources do not provide all four operations and that these are constrained by the privileges of the credentials used when creating the client instance.
The parameters of the methods above vary based on the type of
<resource> you are working with. To get these
details, you can launch a Python interactive session that runs the
client creation script above, and use the ‘help’ command with it. For
example, by using this command for client.organization, you
will find that you can filter the list of organizations (among others)
by name, country, and collaboration:
PYTHON
python -i client.py
>>> help(client.organization)
| list(self, name: 'str' = None, country: 'int' = None, collaboration: 'int' = None, study: 'int' = None, page: 'int' = None, per_page: 'int' = None) -> 'list[dict]'
| List organizations
|
| Parameters
| ----------
| name: str, optional
| Filter by name (with LIKE operator)
| country: str, optional
| Filter by country
| collaboration: int, optional
| Filter by collaboration id. If client.setup_collaboration() was called,
| the previously setup collaboration is used. Default value is None
From parameters like the ones described above, it is important to note that -for the sake of consistency- the client methods use identifiers rather than names. This implies that, for example, to filter the organizations that belong to a a given collaboration, you need to know the collaboration’s identifier first.
You can get these identifiers through the UI, or through the client.
For example, if you need to know the identifiers of the collaborations
you have access to, you can use the list() function of the
client.collaboration resource:
PYTHON
# Get all the details of all the collaborations you have access to:
client.collaboration.list()
# Alternatively, to show only the 'id' and 'name' of each collaboration:
client.collaboration.list(fields=['id', 'name'])Let’s say that with the above you found that the collaboration you need to work with has 45 as an identifier. With this, you can get the details of the organizations that are part of it as follows:
PYTHON
# Get all the organizations that are part of a collaboration whose identifier is 45:
client.organization.list(collaboration=45)
# Get all only the id and name of the organizations that are part of a collaboration whose identifier is 45:
client.organization.list(collaboration=45, fields=['id', 'name'])Creating a new task
To create a new task, that is to say, to request the execution of an
algorithm on a given organization, in the context of a particular
organization, you can use the create() method of the
client.task resource.
This create() method requires a dictionary with
method and kwargs keys as an input.
As an input for the task creation, a dictionary with ‘method’ and
‘kwargs’ keys is required. The value of method must contain
the name of the function to be executed. The kwargs value
must be another dictionary with the properties required by the
algorithm. For example, if you want to create a task with the
federated average algorithm (see original source
code here), the input would look like this:
PYTHON
"""
partial_average() is a function defined on the *federated average* algorithm (see algorithm source at https://github.com/IKNL/v6-average-py/blob/master/v6-average-py/__init__.py). Given that 'colum_name' is the argument required by this function, the value for 'kwargs' key must include a dictionary with this property:
"""
input_ = {
'method': 'partial_average',
'kwargs': {'column_name': 'age'}
}Once you have defined your task input, you can create and start it by also specifying (using identifiers) on which organizations and for which collaboration, it will be executed. In the following example, the partial_average function of the ‘containerized’ algorithm on the ‘harbor2.vantage6.ai/demo/average’ would be executed on the vantage6 nodes created, for the organizations #12 and #23, when setting up the collaboration #45.
Getting a task result
A client’s task execution request is asynchronous. This means that
once the client.task.create() method is invoked, the task
will begin running in the background, returning the control to the
Python program immediately (i.e., without waiting for the task to
complete).
This means that your client program needs to wait until the task is completed, so you can get access to the results (or to the error details, if something goes wrong).
You can use the client.wait_for_result() method to make
the program execution wait until the task is completed. For that, you
need the ID of the task you just created, which was included in the
dictionary returned by the client.task.create() method. For
the task execution request of the code snippet above, this will look
like:
PYTHON
print("Waiting for results")
task_id = average_task['id']
result = client.wait_for_results(task_id)Since the above will pause the execution of the program until the task is completed, you can include instructions for retrieving the results immediately afterward:
Working on the hypothetical case study programatically
Challenge 1 - Setup the node client
The goal of this first challenge is to create a Python script for
performing tasks on Chapter 3’s collaboration projects. Before
installing the vantage6 libraries (which include the client) it is
important to check that these are compatible with the server you will
talk to. Check the version of the server you worked with in Chapter 3 by
accessing its URL including ‘/api/version’ as a suffix (e.g.,
https://SERVER_DOMAIN_NAME/api/version).
Create and activate a Python environment (using conda, venv, etc) and
install the vantage6-client for this particular server
version:
Use one of the researcher credentials and the server URL from Episode 3 to create a configuration file and a script for connecting to the server, following the guidelines provided above. Run the script and check that the connection is performed successfully.
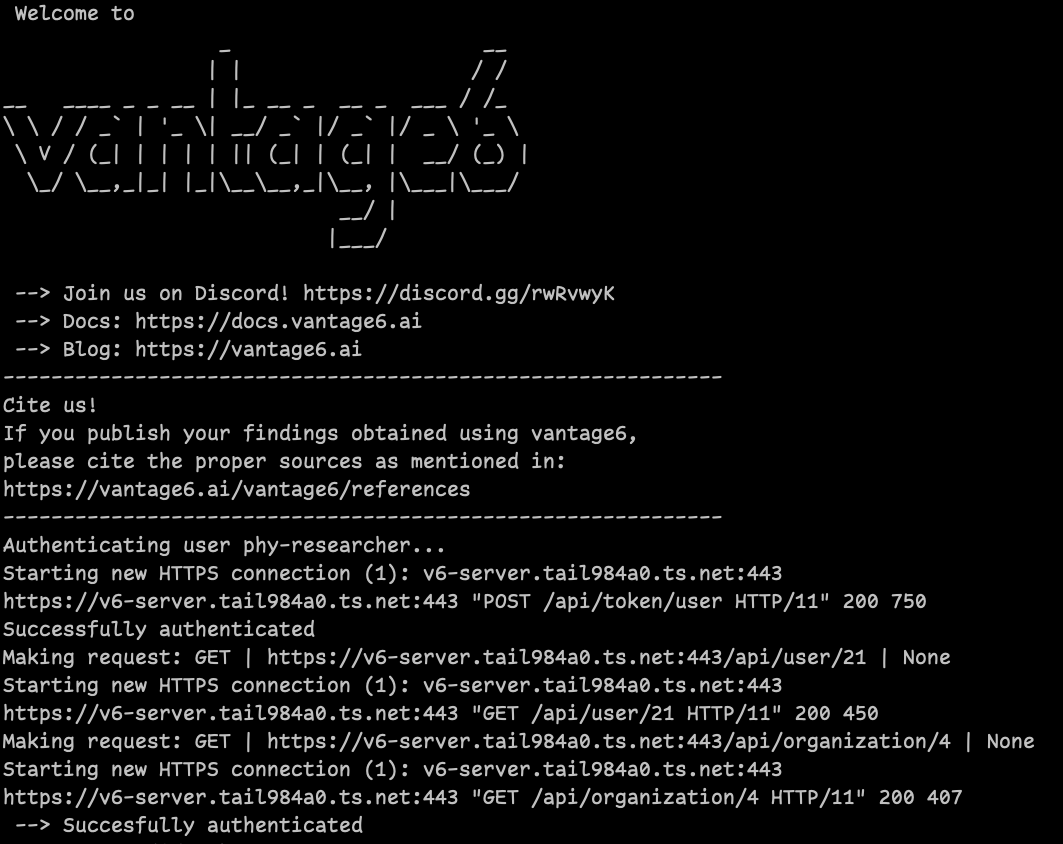
Challenge 2: use the client to find the identifiers of your collaboration and its organizations
Use the researcher credentials from Episode 3, to get the identifiers of the two collaborations from this chapter’s scenario. Use this information to get the identifiers of the organizations that belong to each collaboration.
Refer to the Python client - basic concepts section above to do this.
| User | Roles | Collaboration |
|---|---|---|
| PhY24-rs1 | Researcher | PhY24 |
| GHT-rs1 | Researcher | GHT |
Now, try to identify, programatically, which nodes are active on each
collaboration. Hint: use the client.node resource. Remember
that you can use the help() function to see how to get the
details of the nodes of a given organization.
PYTHON
>>> client.collaboration.list(fields=['id', 'name', 'organizations'])
[
{'id': 4, 'name': 'PhY-research', 'organizations': '/api/organization?collaboration_id=4'},
{'id': 5, 'name': 'GHT_consortium', 'organizations': '/api/organization?collaboration_id=5'}
]By knowing the ID of the collaboration, you can find the identifiers of the organizations that are participating on it:
PYTHON
>>> client.organization.list(collaboration=4)
[
{'address1': '', 'studies': '/api/study?organization_id=3', 'users': '/api/user?organization_id=3', 'zipcode': '', 'domain': '', 'tasks': '/api/task?init_org_id=3', 'public_key': '', 'name': 'CANTABRIA_organization', 'address2': '', 'nodes': '/api/node?organization_id=3', 'country': 'Spain', 'collaborations': '/api/collaboration?organization_id=3', 'runs': '/api/run?organization_id=3', 'id': 3},
{'address1': '', 'studies': '/api/study?organization_id=4', 'users': '/api/user?organization_id=4', 'zipcode': '', 'domain': '', 'tasks': '/api/task?init_org_id=4', 'public_key': '', 'name': 'LIFELINES_organization', 'address2': '', 'nodes': '/api/node?organization_id=4', 'country': 'The Netherlands', 'collaborations': '/api/collaboration?organization_id=4', 'runs': '/api/run?organization_id=4', 'id': 4},
{'address1': '', 'studies': '/api/study?organization_id=5', 'users': '/api/user?organization_id=5', 'zipcode': '', 'domain': '', 'tasks': '/api/task?init_org_id=5', 'public_key': '', 'name': 'GAZEL_organization', 'address2': '', 'nodes': '/api/node?organization_id=5', 'country': 'France', 'collaborations': '/api/collaboration?organization_id=5', 'runs': '/api/run?organization_id=5', 'id': 5},
{'address1': '', 'studies': '/api/study?organization_id=7', 'users': '/api/user?organization_id=7', 'zipcode': '', 'domain': '', 'tasks': '/api/task?init_org_id=7', 'public_key': '', 'name': 'PhY24-consortium', 'address2': '', 'nodes': '/api/node?organization_id=7', 'country': '', 'collaborations': '/api/collaboration?organization_id=7', 'runs': '/api/run?organization_id=7', 'id': 7}
]Getting the status of an organization node for a given collaboration: The following returns the nodes (there is a node for each collaboration the organization contributes to).
PYTHON
>>> client.node.list(organization=4)
[
{'config': [], 'last_seen': '2024-06-18T06:57:48.114072',
'organization': {'id': 4, 'link': '/api/organization/4',
'methods': ['PATCH', 'GET']},
'collaboration': {'id': 4, 'link': '/api/collaboration/4',
'methods': ['GET', 'PATCH', 'DELETE']},
'name': 'PhY-research - LIFELINES_organization', 'status': 'offline',
'type': 'node', 'ip': None, 'id': 13},
{'config': [], 'last_seen': None,
'organization': {'id': 4, 'link': '/api/organization/4',
'methods': ['PATCH', 'GET']},
'collaboration': {'id': 5, 'link': '/api/collaboration/5',
'methods': ['GET', 'PATCH', 'DELETE']},
'name': 'GHT_consortium - LIFELINES_organization', 'status': None,
'type': 'node', 'ip': None, 'id': 18}
]Challenge 3: Creating a task that runs a partial algorithm**
The following is the information of a new algorithm (TODO a new algorithm should be created for this), that you need to use on the collaboration whose 100% of its nodes are active:
- Image: harbor2.vantage6.ai/TODOalg_xxyy
- Functions: central(), partial()
- Algorithm source code: github.com/TODO/repo/alg_xxyy
Using the guidelines given in the Python client - basic
concepts section above, use the client to create a task for
executing the partial() function on all the nodes. Check in
the source code what the parameters of this function are, and define
their input accordingly. For the database selection, all the nodes use
the one labeled as ‘default’.
Include the necessary code to wait until the new task is completed, and to get and print the results. Discuss the output with the instructors.
Challenge 4: Create a task that runs a central function, and figure out why it failed**
Using the Python client, create a new task with the same algorithm
from Challenge #3. This time, launch the central()
function. As you will see, this time the task failed. Using the client,
try to find out which of the nodes involved on the task execution failed
and the error message. Discuss with the instructors, based on the
algorithm source code and the error message the cause of the error, and
what should be done to fix it. (TODO This requires the new
algorithm or the data on one of the nodes to cause an
error)